
8 Data Integration Examples to Boost Your Data Strategy
By Navin Agrawal · Co-Founder & Head of AI, Statisfy
Unifying Your Data Universe: A Deep Dive into Integration Examples
This listicle provides eight detailed data integration examples for IT and customer success professionals. Learn how to leverage data integration techniques to improve customer experiences and streamline operations. We’ll analyze each example, exploring the strategic “why” behind its success and offering actionable takeaways.
This article delivers practical insights you can implement immediately. We’ll cut through the jargon to reveal the core principles and best practices behind effective data integration. Understand the strengths and weaknesses of approaches like ETL, ELT, and API integration. Discover how each method contributes to data-driven decision making and improved customer outcomes.
We’ll explore the following key data integration methods:
- 2. 3. 4. 5. 6. 7. 8.
Effective data integration is crucial for modern businesses. Connecting disparate data sources provides a unified view of customer behavior, operations, and market trends. This unified view empowers informed decision-making, enhanced customer experiences, and ultimately, greater business success. This listicle equips you with the knowledge to select and implement the ideal data integration strategy for your specific needs. Dive in to discover how these examples can transform your data landscape.
1. Extract, Transform, Load (ETL)
ETL is a cornerstone of data integration, especially for building robust data warehouses. This process extracts data from disparate source systems, transforms it to meet business needs and quality standards, and finally loads it into a target destination. This batch-oriented approach, processing data at scheduled intervals, underpins many enterprise data warehousing solutions. It’s a crucial component for organizations seeking to consolidate and analyze their data for informed decision-making. The structured approach provided by ETL offers a reliable framework for handling large volumes of data from various sources.
Examples of ETL in Action
ETL’s power is evident across various industries. Banks use it to process daily transaction summaries, giving them insights into customer behavior and operational efficiency. Retail chains consolidate sales data from multiple stores to analyze product performance and optimize inventory management. Healthcare systems leverage ETL to integrate patient records, enabling better care coordination and research. Even manufacturing companies combine production data from different plants to improve quality control and streamline operations. These examples showcase the versatility of ETL in addressing diverse data integration needs.
Implementing ETL Effectively
Several key considerations contribute to a successful ETL implementation. Designing for incremental loading, where only changed data is processed, drastically improves performance. Comprehensive logging and monitoring provide visibility into the process, allowing for proactive issue resolution. Utilizing parallel processing, where possible, speeds up data processing. Planning for data lineage and auditability ensures data trustworthiness and regulatory compliance. Finally, establishing clear data quality rules upfront minimizes errors and inconsistencies.
The following infographic visually represents the ETL workflow:
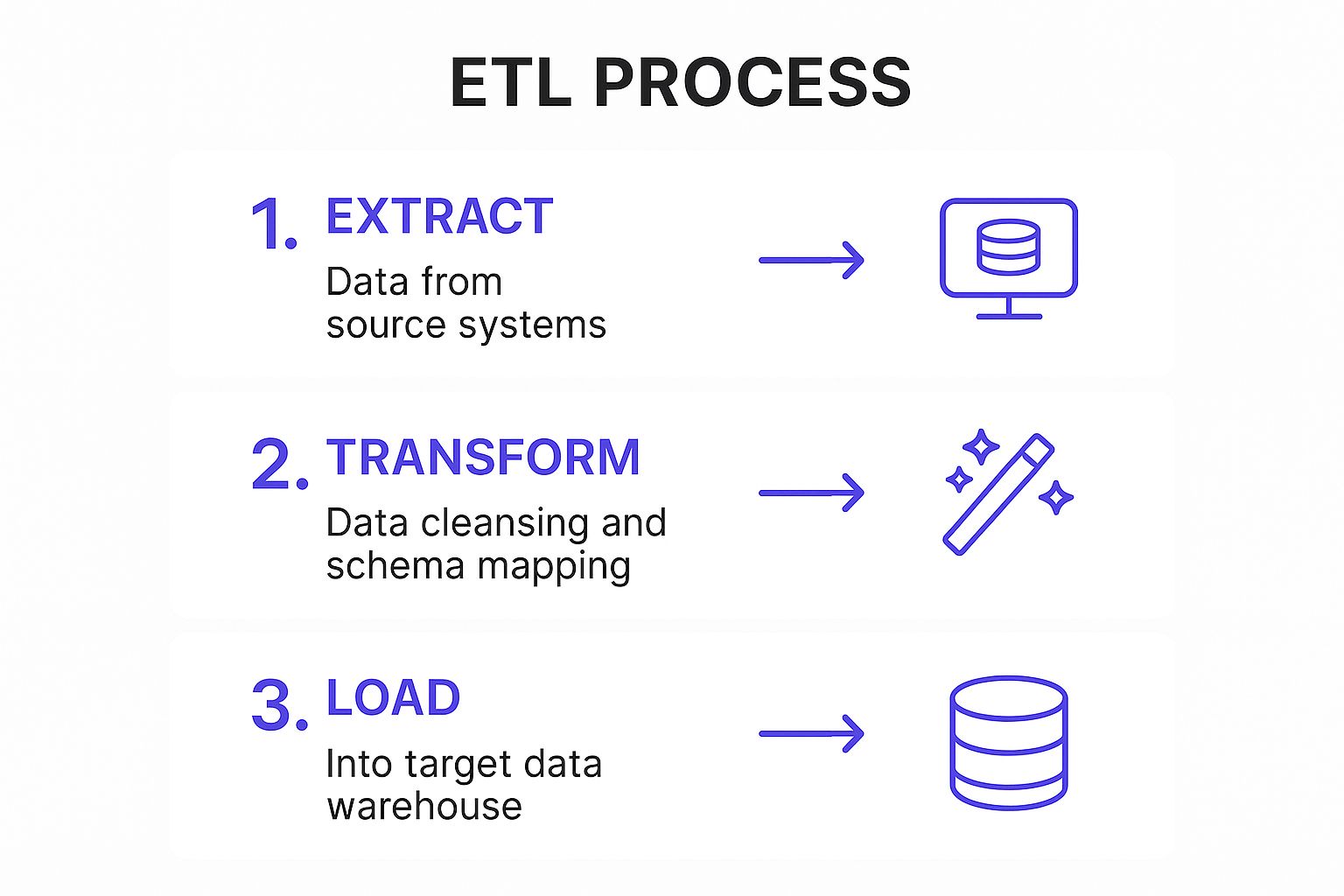
This process flow infographic illustrates the three core stages of ETL: Extract, Transform, and Load. Data is first extracted from various sources, then transformed and cleansed before finally being loaded into the target data warehouse. The sequential nature of this process ensures data integrity and a structured approach to data integration.
Choosing ETL: When and Why
ETL shines when dealing with large volumes of structured data from multiple sources that require significant transformation before analysis. Its batch-oriented nature makes it ideal for scheduled data updates and reports. Tools like IBM InfoSphere DataStage, Microsoft SQL Server Integration Services (SSIS), Informatica PowerCenter, and Talend Data Integration have popularized and streamlined the implementation of ETL processes. Understanding these advantages helps organizations determine if ETL is the right data integration solution for their specific needs. By leveraging the inherent strengths of ETL, organizations can gain valuable insights from their data and empower data-driven decisions.
2. Extract, Load, Transform (ELT)
ELT is a modern variation of ETL where raw data is first loaded into the target system before transformation. This approach utilizes the processing power of the destination platform, such as a cloud data warehouse, to perform transformations. This method is particularly effective with modern data lakes and cloud data warehouses that offer massive parallel processing capabilities. ELT leverages the scalability and cost-effectiveness of cloud computing for enhanced data integration.
Examples of ELT in Action
Snowflake data warehouse implementations frequently utilize ELT. Its powerful processing engine allows for complex transformations directly within the platform. Amazon Redshift analytics workloads also benefit from ELT, enabling rapid data loading and subsequent transformation. Google BigQuery data processing and Azure Synapse Analytics solutions further demonstrate the effectiveness of ELT across various cloud environments. These platforms provide the infrastructure necessary to handle the volume and velocity of data typically associated with ELT processes.
Implementing ELT Effectively
Several key considerations ensure successful ELT implementation. Ensure the target system has sufficient processing power to handle the transformations efficiently. Implement data quality checks post-load to identify and rectify any inconsistencies. Use columnar storage for better performance during transformations. Design for data governance and security to protect sensitive information. Finally, monitor resource utilization during transformations to optimize performance and control costs. These practices ensure efficient and reliable data integration using ELT.
Choosing ELT: When and Why
ELT shines when dealing with large volumes of raw data, especially semi-structured or unstructured data, destined for cloud-based data warehouses or data lakes. Its ability to leverage the target system’s processing power makes it highly scalable and cost-effective. Tools like Fivetran, Matillion, and Stitch have popularized and streamlined the implementation of ELT processes by simplifying data ingestion and transformation. Understanding these advantages helps organizations determine if ELT is the right data integration solution for their specific needs. By harnessing the power of cloud computing, ELT empowers organizations to gain insights from their data faster and more efficiently. It represents a significant shift in how data integration is approached in the modern data-driven world.
3. Application Programming Interface (API) Integration
API integration enables real-time data exchange between systems through standardized interfaces, typically using REST, SOAP, or GraphQL protocols. This method allows applications to communicate directly, sharing data on-demand without the need for batch processing or intermediate storage systems. This real-time capability is crucial for modern businesses that rely on up-to-the-minute information.

Examples of API Integration in Action
API integration is ubiquitous in today’s interconnected world. Salesforce CRM integrating with marketing automation platforms provides a seamless flow of lead information. E-commerce platforms connecting with payment gateways enable secure and efficient transactions. Mobile apps synchronizing with cloud databases offer consistent user experiences across devices. Social media platforms sharing data with third-party applications broaden their reach and functionality. These examples demonstrate the wide applicability of API integration across various industries.
Implementing API Integration Effectively
Several key considerations are essential for effective API integration. Implementing proper authentication and rate limiting safeguards data and ensures service stability. Designing for API versioning from the start allows for future updates without disrupting existing integrations. Employing caching strategies reduces API calls and improves performance. Monitoring API performance and availability provides insights into potential bottlenecks. Implementing retry logic and error handling enhances resilience.
Choosing API Integration: When and Why
API integration is the ideal choice for real-time data exchange, event-driven architectures, and connecting cloud-based services. Its on-demand nature makes it highly efficient for applications requiring immediate access to data. Platforms like Salesforce, Stripe, Twitter, Google, and Amazon have popularized and standardized API usage. Understanding the strengths of API integration allows organizations to leverage its capabilities for seamless data sharing and enhanced interoperability. By adopting a well-planned API strategy, businesses can improve agility and responsiveness in today’s dynamic digital landscape.
4. Database Replication
Database replication is a crucial data integration method that maintains identical copies of data across multiple database instances. This process ensures data consistency and availability by automatically synchronizing changes from a master database to one or more replica databases. Replication supports both real-time and near real-time scenarios, making it a versatile solution for various data integration needs. It’s a fundamental technique for improving application performance, ensuring business continuity, and enabling data distribution across different locations.
Examples of Database Replication in Action
The power of database replication is evident in diverse applications. MySQL’s master-slave replication is frequently used for read scaling, allowing applications to handle a higher volume of read queries by distributing them across multiple replicas. PostgreSQL’s streaming replication provides high availability, ensuring continuous operation even if the master database fails. Oracle Data Guard is a robust solution for disaster recovery, enabling rapid recovery in case of catastrophic events. SQL Server’s Always On Availability Groups offers similar functionality, facilitating high availability and disaster recovery. These examples showcase the diverse applications of database replication across various database platforms.
Implementing Database Replication Effectively
Successful database replication implementations depend on several key factors. Choosing the appropriate replication topology (master-slave, master-master, etc.) is crucial for meeting specific requirements. Regularly monitoring replication lag, the delay between changes on the master and their reflection on replicas, helps ensure data consistency and identify potential bottlenecks. Resolving any replication conflicts promptly is essential for maintaining data integrity. Implementing robust backup strategies for all replicas safeguards against data loss. Regular testing of failover procedures validates the system’s resilience. Finally, considering network bandwidth and latency requirements is critical for optimal performance.
Choosing Database Replication: When and Why
Database replication is an excellent choice when high availability, disaster recovery, and read scaling are paramount. It’s particularly valuable for applications with high read loads, where distributing queries across multiple replicas significantly improves performance. In mission-critical systems, database replication provides a robust mechanism for ensuring business continuity. Understanding the various replication topologies and their respective strengths and weaknesses is vital for selecting the most appropriate approach. By leveraging database replication effectively, organizations can enhance application performance, improve data availability, and ensure data resilience.
5. Message Queue Integration
Message queue integration uses messaging middleware to facilitate asynchronous communication between systems. Data is packaged into messages and placed in queues. This allows systems to process information at their own pace, ensuring reliable delivery and decoupling sender and receiver systems. This decoupling is crucial for building resilient and scalable applications, as it prevents cascading failures and allows individual services to evolve independently.

Examples of Message Queue Integration in Action
Message queues are a fundamental component of modern distributed systems. Apache Kafka excels at real-time data streaming, enabling applications like fraud detection and log aggregation. RabbitMQ is a popular choice for microservices communication, facilitating seamless data exchange between independent services. Amazon SQS simplifies cloud-based queuing, offering a managed service for reliable message delivery. Apache ActiveMQ provides robust enterprise messaging capabilities, supporting a wide range of integration scenarios. These diverse applications showcase the versatility of message queue integration across various industries.
Implementing Message Queue Integration Effectively
Successful message queue integration hinges on careful planning and execution. Designing idempotent message processors prevents duplicate processing when messages are redelivered. Implementing proper message serialization ensures compatibility between different systems. Monitoring queue depths and processing rates helps identify bottlenecks and optimize performance. Utilizing dead letter queues provides a mechanism for handling failed messages, preventing data loss. Considering message ordering requirements is essential for applications where sequence is crucial, like financial transactions.
Choosing Message Queue Integration: When and Why
Message queue integration is ideal when dealing with asynchronous data flows and high-volume data streams. Its decoupled nature promotes system resilience and scalability. Choose this method when integrating systems with different processing speeds or availability requirements. This approach is particularly valuable for real-time data processing, event-driven architectures, and microservices communication. By leveraging the strengths of message queue integration, organizations can build robust and flexible data integration solutions. Understanding the nuances of message queue systems like Kafka, RabbitMQ, SQS, and ActiveMQ empowers informed decision-making when selecting the best tool for specific data integration needs.
6. Change Data Capture (CDC)
Change Data Capture (CDC) is a powerful data integration method that identifies and captures changes made to data in a database. It then delivers those changes in real-time to downstream systems like data warehouses, data lakes, or other operational databases. This allows for near real-time data synchronization without impacting the performance of the source system. CDC achieves this by monitoring database transaction logs, efficiently detecting inserts, updates, and deletes.
Examples of CDC in Action
CDC is invaluable for businesses needing real-time data insights. For example, e-commerce platforms use CDC to update inventory levels instantly after each purchase, ensuring accurate stock information for customers. Financial institutions leverage CDC to track transactions in real-time for fraud detection and risk management. Social media platforms employ CDC to update user feeds with new posts and activities as they occur. These examples demonstrate the breadth of CDC applications across diverse industries. Tools like Debezium for Apache Kafka CDC, AWS Database Migration Service (DMS) CDC, Oracle GoldenGate, and Microsoft SQL Server Change Tracking offer robust solutions for implementing CDC.
Implementing CDC Effectively
Successful CDC implementation hinges on several key considerations. Starting with pilot projects on a smaller scale allows teams to gain experience and refine their approach. Continuous monitoring of change data volumes and processing lag helps ensure optimal performance. Implementing robust error handling and recovery mechanisms is crucial for maintaining data integrity and system stability. Planning for schema evolution and Data Definition Language (DDL) changes ensures compatibility as the source database evolves. Finally, using appropriate filtering mechanisms allows for efficient management of data volumes and prevents downstream systems from being overwhelmed.
Choosing CDC: When and Why
CDC excels in scenarios requiring real-time data synchronization and low-impact data extraction. Its ability to capture changes as they occur makes it ideal for applications needing up-to-the-minute data, such as real-time analytics, operational reporting, and event-driven architectures. CDC is particularly beneficial when minimizing the load on source systems is paramount. While traditional ETL processes can achieve similar outcomes, CDC provides a more efficient and less intrusive method for capturing and delivering change data. This makes CDC a critical data integration example for modern businesses demanding real-time insights. By leveraging the power of CDC, organizations can unlock the full potential of their data and drive faster, more informed decision-making.
7. Data Virtualization
Data virtualization creates a virtual layer providing unified access to data from multiple sources without physically moving or copying it. This approach allows users to query and analyze data from various systems through a single interface. It offers real-time access while maintaining data in its original locations. This eliminates the need for complex data movement and transformation processes, simplifying data integration significantly.
Examples of Data Virtualization in Action
Data virtualization’s agility shines in scenarios requiring rapid access to diverse data. A financial institution could leverage data virtualization to combine customer data from core banking systems, CRM, and loan origination systems for a 360-degree customer view. This enables personalized financial advice and risk assessment without data replication. Similarly, an e-commerce company could integrate product information from various databases and APIs. This empowers customer service representatives to access real-time inventory and pricing data for faster query resolution and improved customer experience.
Implementing Data Virtualization Effectively
Several best practices contribute to successful data virtualization implementations. Intelligent caching strategies enhance performance by storing frequently accessed data in memory. Optimized network connectivity between sources and the virtual layer is crucial for minimizing latency. Data virtualization is particularly suited for read-heavy workloads where data transformation is minimal. Regularly monitoring query performance and optimizing accordingly ensures consistent responsiveness. Finally, implementing robust security and access controls protects sensitive data within the virtualized environment.
Choosing Data Virtualization: When and Why
Data virtualization excels when real-time data access, agility, and cost-effectiveness are paramount. It’s ideal for integrating data from cloud and on-premises sources, enabling a hybrid data architecture. Data virtualization reduces the complexity and cost of traditional ETL processes. Tools like Denodo Platform, IBM Cloud Pak for Data virtualization, Red Hat JBoss Data Virtualization, and TIBCO Data Virtualization offer robust platforms for implementing data virtualization solutions. Understanding these advantages helps organizations decide if data virtualization is the right data integration solution for their specific needs. By leveraging its strengths, organizations unlock valuable data insights and empower agile decision-making. This is particularly valuable in today’s rapidly changing business environment, where quick access to accurate data is a competitive advantage.
8. Webhook Integration
Webhook integration is a powerful method for achieving real-time data synchronization between different systems. It leverages HTTP callbacks to push data updates automatically whenever specific events occur. Unlike traditional polling, which requires constant checks, webhooks provide instant notifications, significantly improving efficiency and reducing latency. This event-driven approach makes webhooks ideal for scenarios demanding immediate data synchronization.
Examples of Webhook Integration in Action
Several platforms effectively utilize webhooks. GitHub uses them to trigger automated builds and deployments upon code changes. Stripe employs webhooks to notify businesses of successful payments, enabling real-time order fulfillment. Shopify leverages webhooks to update inventory levels across platforms whenever a sale occurs. Slack integrates webhooks to streamline team communication by posting notifications from various tools directly into channels. These diverse applications demonstrate the versatility and power of webhook integration for data integration examples.
Implementing Webhook Integration Effectively
Successful webhook implementation hinges on several best practices. Designing idempotent webhook handlers ensures data consistency even if the same webhook is received multiple times. Using HTTPS and signature verification strengthens security and protects against malicious requests. Implementing proper logging and monitoring allows for efficient troubleshooting and proactive issue resolution. Handling webhook failures gracefully with retry mechanisms ensures data reliability. Finally, thorough testing of webhook endpoints validates functionality and prevents unexpected issues.
Choosing Webhook Integration: When and Why
Webhook integration excels in event-driven scenarios where real-time data synchronization is crucial. It significantly reduces the overhead associated with traditional polling methods, making it ideal for applications requiring immediate responses to changes. Popularized by platforms like GitHub, Stripe, Shopify, PayPal, and Slack Technologies, webhooks have become an essential tool for building responsive and interconnected systems. Understanding the benefits of webhooks empowers organizations to choose the right data integration solution for their specific real-time data requirements. Leveraging webhooks effectively enhances efficiency and facilitates data-driven decision-making.
Data Integration Methods Comparison
Integration MethodImplementation Complexity 🔄Resource Requirements ⚡Expected Outcomes 📊Ideal Use Cases 💡Key Advantages ⭐Extract, Transform, Load (ETL)High: multi-stage, complex maintenanceHigh: intensive during batch windows, storage neededHigh data quality, batch-processed dataLarge-scale batch processing, data warehousing, complex transformationsMature process, strong data quality, error handlingExtract, Load, Transform (ELT)Medium: depends on target system capabilitiesModerate: leverages cloud processing powerFaster loading, flexible transformationsCloud data warehouses, big data, rapid ingestionScalability, lower infrastructure cost, cloud-nativeAPI IntegrationMedium: requires error handling, versioning managementLow to Moderate: network-dependentReal-time data exchange, low latencyReal-time integrations, microservices, mobile appsReal-time sync, standardized protocols, flexibilityDatabase ReplicationHigh: managing multiple DB instances and conflictsHigh: network bandwidth, licensing for replicasHigh availability, near real-time syncHigh availability, disaster recovery, read scalingAutomatic failover, load distribution, disaster recoveryMessage Queue IntegrationMedium to High: middleware setup, monitoring requiredModerate: additional middleware infrastructureAsynchronous, reliable, scalable processingMicroservices, event-driven systems, high-volume streamingLoose coupling, fault tolerance, high scalabilityChange Data Capture (CDC)High: complex setup, DB-specific implementationModerate: depends on change volume and monitoringNear real-time sync, low source impactReal-time analytics, data lake ingestion, operational reportingReal-time changes capture, incremental loadsData VirtualizationHigh: query optimization and network dependencyLow to Moderate: no data duplication, caching helpsReal-time unified data accessSelf-service analytics, data exploration, reduce data movementNo data duplication, fast insights, simplified governanceWebhook IntegrationLow to Medium: simple setup, but requires secure endpointsLow: minimal server load compared to pollingInstant data push, event-drivenEvent-driven integrations, real-time notifications, SaaSInstant delivery, reduced load, cost-effective
Integrating Your Way to Success: Key Takeaways and Next Steps
This exploration of data integration examples has showcased a range of approaches, from established ETL processes to modern real-time methods like webhooks and change data capture. Each method, including API integration, database replication, message queues, and data virtualization, offers distinct advantages and disadvantages. Choosing the right approach hinges on understanding your specific business requirements and objectives.
The Power of Strategic Data Integration
Effective data integration isn’t just about moving data; it’s about leveraging that data for strategic advantage. Whether you’re aiming to improve customer experiences, streamline operations, or enhance decision-making, data integration plays a crucial role. By connecting disparate systems, you unlock valuable insights hidden within isolated data silos. This enables businesses to get a 360-degree view of their customers and operations.
Actionable Insights for Implementation
Throughout this article, we’ve delved into the “why” behind successful data integration strategies. Key takeaways include:
Understanding Your Data: Begin by thoroughly assessing your current data landscape, identifying sources, formats, and desired outcomes. This initial step informs your integration approach and sets the stage for success.
Choosing the Right Tool: Select integration methods aligned with your data volume, velocity, and complexity. Consider factors like real-time requirements, data transformation needs, and resource constraints.
Prioritizing Data Quality: Maintaining data integrity throughout the integration process is paramount. Implement validation checks and cleansing processes to ensure accuracy and reliability.
Focusing on Business Value: Align your integration strategy with specific business objectives. Measure the impact of your efforts by tracking key performance indicators (KPIs) relevant to your goals.
Data Integration Examples: Putting it All Together
The data integration examples discussed provide a solid foundation for building your own strategy. By understanding the nuances of ETL versus ELT, the power of APIs, and the benefits of real-time integration, you can tailor your approach to maximize impact. Remember that successful data integration is an iterative process. Continuous monitoring, refinement, and adaptation are crucial for long-term success.
The Future of Data Integration and Customer Success
As businesses increasingly rely on data-driven insights, the importance of seamless data integration will only grow. Mastering these concepts empowers organizations to unlock the full potential of their data, leading to improved customer relationships, optimized operations, and enhanced competitiveness. Investing in robust data integration capabilities is not just a technical necessity; it’s a strategic imperative for businesses looking to thrive in the modern data-driven landscape.
Ready to streamline your customer success efforts and unlock the power of data integration? Statisfy offers AI-driven insights and seamless data integration capabilities to help you maximize revenue, agility, and long-term customer satisfaction. Explore how Statisfy can revolutionize your customer management by visiting Statisfy.