
Data Pipeline Automation for Modern Workflows
By Navin Agrawal · Co-Founder & Head of AI, Statisfy
Imagine a modern factory floor. You don’t see workers carrying parts from one station to the next by hand. Instead, you see a sophisticated assembly line, a system of conveyor belts and robotic arms that takes raw materials and turns them into a finished product, all without stopping.
That, in a nutshell, is what data pipeline automation does for your data. It’s the technology that automatically moves raw data from all your different sources, cleans and shapes it into a useful format, and then delivers it for analysis—all without someone needing to manually click “run.”
What Is Data Pipeline Automation Anyway?
At its heart, data pipeline automation is about creating a self-running, hands-off system for all your data flows.
Think about the old way of doing things. Managing data manually is like a bucket brigade at a fire. An engineer has to grab a “bucket” of data from one system, run it over to another, clean it up by hand, and then finally pass it off for someone else to use. This isn’t just slow and mind-numbingly tedious; it’s a recipe for disaster. One slip-up, one tiny mistake, can contaminate an entire dataset, leading to bad reports and even worse business decisions.
Data pipeline automation gets rid of the bucket brigade and replaces it with a seamless, programmatic flow. It’s a digital conveyor belt that runs 24/7, making sure data gets from point A to point B efficiently and reliably. This isn’t just a small tweak; it’s a completely different way of thinking about how companies manage their most valuable asset. The economic impact speaks for itself—the global market for data pipeline tools was valued at roughly $11.24 billion and is expected to hit $13.68 billion the following year, a healthy growth rate of about 21.8%. You can dig deeper into these trends in this detailed data pipeline tools market analysis.
The Automated Advantage Over Manual Methods
The difference between a manual and an automated pipeline is night and day. While they both have the same goal—moving data—how they get there and the results they produce are worlds apart. Manual pipelines rely on engineers to write and run scripts for every single step, a method that just can’t keep pace with the sheer amount of data businesses deal with today.
On the other hand, an automated pipeline is built from the ground up for reliability and scale. It uses orchestration tools to schedule, run, and monitor entire workflows, making sure every task happens in the right order and on time.
This approach breaks the operational bottleneck. It frees up your team from the constant, repetitive work of just keeping the lights on. Instead, they can focus their brainpower on what really matters, like building new data products or uncovering game-changing insights.
To really see the difference, let’s compare them side-by-side.
Comparing Manual vs Automated Data Pipelines
This table breaks down the fundamental differences between the two approaches, showing why automation has become the standard for modern data teams. AspectManual Data PipelineAutomated Data PipelineExecutionRequires constant human intervention and manual scripting.Runs automatically based on schedules or triggers.SpeedSlow, with significant delays between data availability and insights.Near real-time or frequent batch updates for faster insights.ReliabilityHigh risk of human error, leading to inconsistent data quality.Consistent and repeatable, minimizing errors.ScalabilityDifficult and resource-intensive to scale with growing data volumes.Designed to handle large, fluctuating data loads efficiently.MaintenanceHigh, requiring continuous developer time for upkeep and fixes.Low, with built-in monitoring and alerting for proactive issue resolution. Ultimately, switching to data pipeline automation isn’t just a technical upgrade; it’s a strategic one. It gives your organization the ability to make quicker, more confident decisions because you can finally count on a constant stream of clean, reliable, and timely data.
The Real-World Benefits of Automating Data Pipelines

Let’s move beyond theory. The practical advantages of data pipeline automation show up directly in your business results. When you automate how data moves through your company, you’re not just making a technical tweak—you’re making a strategic decision. This leads to cleaner data, more efficient operations, and a real competitive advantage because you can get insights faster than ever before.
This isn’t just a fleeting trend; it’s a fundamental shift. The global market for data pipeline tools, recently valued at $10.22 billion, is expected to jump to $12.53 billion next year. That kind of growth tells you just how critical automation is becoming for handling today’s data deluge. If you want to dive deeper, you can check out these detailed data pipeline tools market insights.
Elevate Data Quality and Trust
Let’s be honest: human error is one of the biggest risks to data integrity. No matter how careful your team is, manual data entry and processing will always introduce mistakes. A simple typo, a wrong format, or a missed update can snowball into huge problems, leading to bad analysis and even worse decisions.
Data pipeline automation stops these errors before they start. You define the rules and validation checks once, and the system applies them flawlessly every single time.
- Automated Validation: Your pipeline can automatically scan for empty fields, duplicates, or weird data types. It flags or quarantines this bad data before it ever contaminates your reports.- Consistent Transformations: Every piece of data gets the same treatment. This guarantees uniformity, which is essential when you’re dealing with massive datasets.- Complete Audit Trails: Automation creates a crystal-clear log of every single thing that happens to your data. This makes it much easier to track down problems or prove compliance.
Ultimately, this consistency builds trust. When your leadership team knows the data is solid, they can make bold decisions with confidence.
Boost Operational and Team Efficiency
Your data engineering team is incredibly valuable. So why is their time often spent on boring, repetitive tasks? Manually running scripts, troubleshooting jobs that failed overnight, and patching together data flows is a massive drain on both resources and morale.
Automating these workflows frees your engineers from the daily grind of firefighting. Instead of propping up fragile manual processes, they can focus their brainpower on what really matters: building new data products, optimizing system performance, and exploring innovative data sources.
This shift directly fuels productivity and creativity. When you empower engineers to solve bigger, more interesting problems, the entire business wins. This efficiency isn’t just for general operations, either. It can be applied to specialized fields like environmental reporting. For anyone interested in that space, you can learn more about achieving carbon data automation for efficiency.
Accelerate Time-to-Insight
In today’s market, the faster you get insights, the faster you can act. Manual pipelines create a frustrating lag between when data is created and when it’s actually useful. That delay could mean missing a golden market opportunity or failing to spot a crisis before it gets out of hand.
Automated pipelines completely eliminate this lag. They can run continuously or on a tight schedule, making sure that fresh, reliable data is always on hand for analysis.
Consider this real-world retail example:
Imagine a retail chain trying to analyze daily sales to manage inventory and tweak marketing campaigns.
- The Manual Way: Every morning, an analyst spends hours pulling sales data from dozens of stores, cleaning it up, and loading it into a spreadsheet. By the time the report is ready, the analysis is already a day old.- The Automated Way: The pipeline runs on its own overnight. By 9 AM, every manager has a dashboard with the previous day’s complete, validated sales data. They can make decisions immediately.
This speed—from raw data to actionable insight—is what allows organizations to become truly agile and responsive. It’s how data goes from being a chore to being your greatest strategic asset.
Deconstructing an Automated Data Pipeline
To really get what makes data pipeline automation tick, you have to look under the hood. An automated pipeline is a lot like a complex machine, built from several core parts that each have a specific, crucial job. When all these pieces work in sync, they create a self-sufficient system that shuttles data from point A to point B with incredible speed and accuracy.
This diagram lays out the fundamental stages of the process.
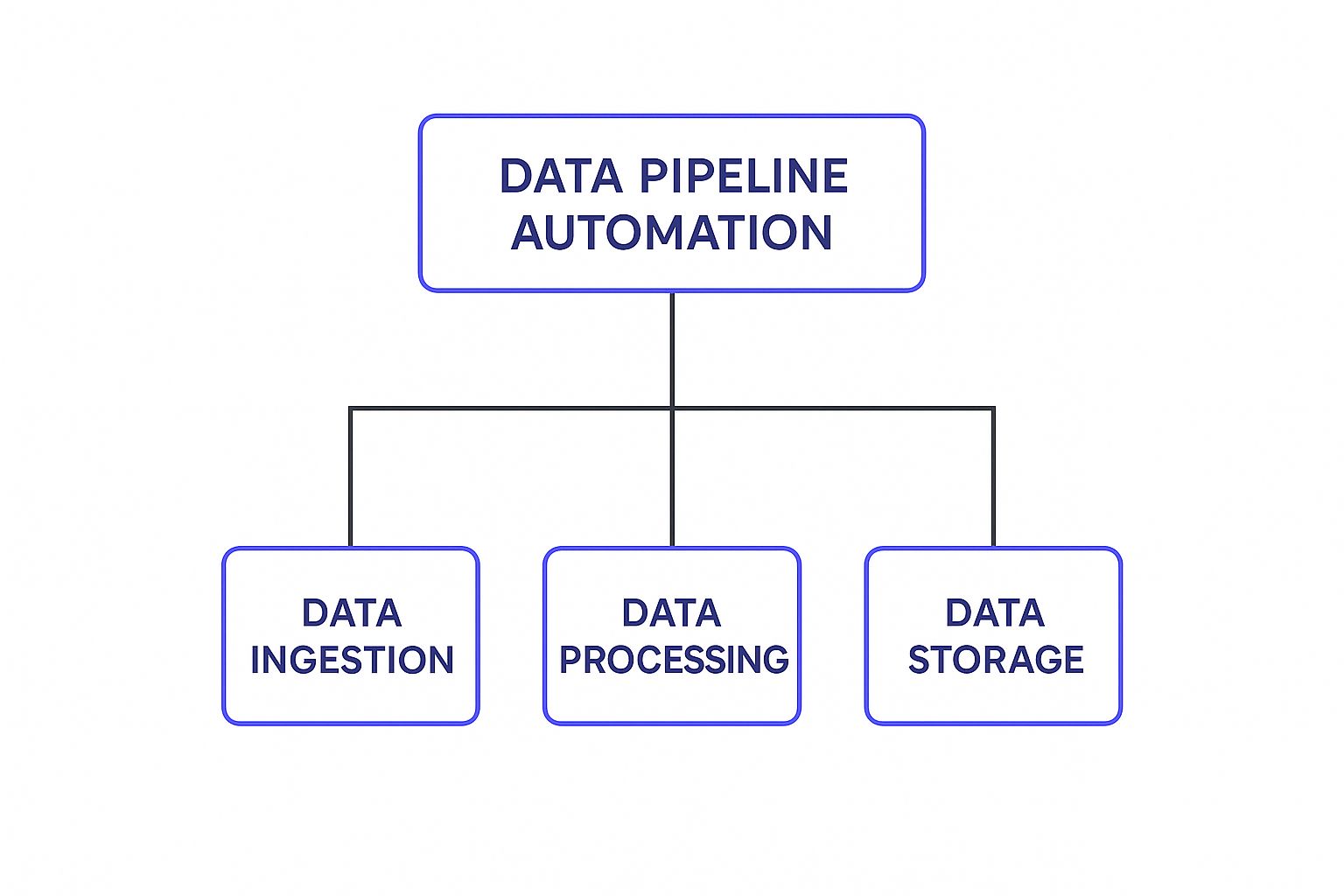
As you can see, it boils down to three key pillars: getting the data in (Ingestion), making it useful (Processing), and keeping it safe (Storage). Let’s dive into each of these, along with a couple of other vital components, to see how it all comes together.
Data Sources: The Origin Points
Every data pipeline has a beginning. These starting points, or data sources, are the different places where your raw data is first created and stored. The sheer variety of potential sources is why you need a flexible system that can connect to just about anything.
You’ll typically find data coming from places like:
- Transactional Databases: The MySQL or PostgreSQL databases that run your day-to-day business apps.- SaaS Platforms: Cloud-based tools like Salesforce, HubSpot, or Zendesk that house essential customer data.- IoT Devices: A constant stream of operational data from sensors and smart equipment.- APIs and Webhooks: Interfaces that let you pull data from social media platforms or other third-party services.
The big challenge here is that every source speaks its own “language,” with unique formats and structures. A good automated pipeline has to act as a universal translator.
Data Ingestion: The Entry Ramp
Once you’ve pinpointed your sources, the next job is ingestion—the actual process of pulling that data into your pipeline. Think of it as the on-ramp to a data highway. The main goal is to get data out of its siloed system and onto the main road where its journey can start.
There are two main ways to get this done:
- 2.
Which method you choose really just depends on your business goals and how quickly you need fresh data.
Data Transformation: The Assembly Station
Raw data is almost never ready for analysis right out of the box. It tends to be messy, inconsistent, and unstructured. That’s where transformation steps in. If ingestion is the on-ramp, transformation is the quality control and assembly station where raw materials get turned into a polished, finished product.
This stage is arguably the most important for making sure your data is high-quality and usable. It’s where you apply business logic to make the data not just clean, but meaningful.
During transformation, your pipeline will handle a few key jobs:
- Cleaning: Fixing typos, dealing with missing values, and getting rid of duplicate records.- Standardizing: Making sure all data follows a consistent format (e.g., ensuring all dates look like
YYYY-MM-DD).- Enriching: Combining data from multiple sources to build a richer view, like adding demographic details to a customer profile.- Aggregating: Summarizing data to a higher level, like calculating total daily sales from thousands of individual transaction records.
If you skip this step, you’re just feeding your analytics tools unreliable garbage, which will only lead to bad decisions. To truly see the power of your automated flows, you need to understand the techniques for building custom analytics dashboards.
Data Storage and Orchestration: The Warehouse and Command Center
After the data is cleaned and prepped, it needs a permanent home. This could be a data warehouse like Google BigQuery for structured data ready for analysis, or a data lake for storing massive amounts of both raw and processed data. The right storage choice really hinges on what you plan to do with the data later on.
Of course, none of this happens by magic. The entire show is run by an orchestrator. Tools like Apache Airflow or managed services like AWS Step Functions act as the pipeline’s brain or project manager. The orchestrator schedules jobs, manages which tasks depend on others, and retries any steps that fail. It’s the component that ensures every part of the process runs in the right order and at the right time, turning a bunch of separate tasks into a single, automated workflow.
Popular Tools for Each Pipeline Stage
With all these moving parts, it’s helpful to know what tools people actually use to build these pipelines. Different tools specialize in different stages, from pulling data to managing the workflow. Pipeline StageTool CategoryExample ToolsIngestionETL/ELT PlatformsFivetran, Stitch, AirbyteTransformationData Transformation Toolsdbt, SQLStorageCloud Data WarehousesSnowflake, Google BigQuery, Amazon RedshiftOrchestrationWorkflow OrchestratorsApache Airflow, Prefect, Dagster This table gives you a snapshot of the modern data stack. While some platforms offer all-in-one solutions, many of the best pipelines are built by combining these specialized, best-in-class tools to fit a company’s unique needs.
Your Blueprint for a Successful Implementation

Getting data pipeline automation right is about much more than just picking the newest, shiniest tools. It requires a thoughtful, deliberate strategy. Without one, you’re setting yourself up for tangled workflows, surprise costs, and a very frustrated team. It’s like building a house—you’d never start pouring concrete without a detailed blueprint.
A strategic approach ensures your automated pipelines don’t just function, but actually deliver real business value. The goal is to build a data infrastructure that’s resilient, efficient, and secure from the ground up, sidestepping the common pitfalls that trip up so many projects.
Start With a Clear Data Strategy
Before a single line of code gets written or a new subscription is activated, you have to define what success actually looks like. Your data strategy is that essential blueprint for the entire project. It’s where you answer the fundamental questions that will steer every decision down the road.
Start by getting your stakeholders in a room and asking the tough questions:
- What specific business problems are we trying to solve with this data?- Which key performance indicators (KPIs) will these pipelines ultimately power?- Who needs access to the data, and how fresh does it need to be?
Answering these up front keeps you from building a technically flawless pipeline that solves the wrong problem. It directly connects your engineering efforts to tangible business goals, guaranteeing the end result is actually useful.
Select the Right Tools for Your Team and Scale
The market for automation tools is crowded, making it easy to get overwhelmed. The trick is to find technology that genuinely fits your organization’s unique situation, not just what’s trending on social media.
Think through these factors as you evaluate your options:
- Team Skillset: Is your team full of seasoned data engineers who live and breathe code-heavy tools like Apache Airflow? Or do you need a low-code platform that lets business analysts get their hands dirty? Matching tools to existing skills drastically cuts down the learning curve.- Scalability: Do you expect your data volume to grow 10x in the next two years? Look for tools that can handle your future, not just your present. This is where cloud-native solutions often shine.- Integration Needs: Make a complete inventory of your data sources and destinations. Your chosen tool absolutely must have reliable, pre-built connectors for the systems you rely on every day.
A classic mistake is to over-engineer the solution. Sometimes, a simple, managed ETL service is a far better choice for a small team than a sprawling, self-hosted orchestration platform. Start with what you need now, but have a clear plan for how you’ll grow.
Build for Observability and Monitoring
An automated pipeline that runs silently is fantastic—right up until it fails silently. Without great monitoring, a broken pipeline can go unnoticed for hours or even days, polluting your analytics systems with bad data and destroying trust. This is why observability—the ability to understand what’s happening inside your system just by looking at its outputs—is completely non-negotiable.
Your monitoring strategy should cover a few key bases:
- Alerting: Set up immediate notifications for pipeline failures, data quality anomalies, or significant processing delays.- Logging: Use structured logging to make troubleshooting a breeze. When something breaks, your engineers should be able to see exactly what happened and why.- Dashboards: Build a central command center with dashboards showing the health and performance of all your pipelines at a glance.
This proactive mindset transforms your team from constantly putting out fires to proactively managing a healthy system.
Embed Governance and Security From Day One
Data governance and security can’t be an afterthought. They must be woven into the very fabric of your automation strategy right from the beginning. Pushing them to the end is a recipe for compliance headaches and serious data breaches. While the context is different, the principles of structured, secure automation in a CI/CD pipeline tutorial share a similar DNA.
Focus on establishing clear rules for:
- 2. 3.
By integrating these practices early, you build a data pipeline automation framework that isn’t just powerful and efficient—it’s also secure and trustworthy, setting your organization up for real, long-term success.
Navigating Common Automation Challenges
Building a powerful, automated data pipeline is a fantastic goal, but let’s be honest—the path to get there is rarely a straight line. For all the talk about the benefits, the real world is messy. The journey is often littered with frustrating obstacles that can stop even the sharpest data teams in their tracks. Knowing what these hurdles are ahead of time is half the battle.
So, to successfully implement data pipeline automation, you need to be ready for these challenges. Let’s walk through the most common roadblocks I’ve seen and talk about practical ways to get around them, so your pipelines aren’t just working, but are built to last.
Taming Intricate Task Dependencies
One of the first big headaches you’ll run into is managing complex dependencies. Modern data pipelines aren’t simple, one-way streets. They’re more like a tangled web of tasks where one step can’t kick off until several others have finished perfectly. If a single upstream task fails, it can create a domino effect, bringing the whole operation grinding to a halt.
Trying to track all these connections by hand is a recipe for disaster, especially as things scale. This is precisely where a good workflow orchestrator becomes your best friend.
- Use a Workflow Orchestrator: Tools like Apache Airflow, Prefect, or Dagster were built for this. They let you define all these complex relationships as code, giving you a clear visual map (a Directed Acyclic Graph, or DAG) of your entire workflow.- Implement Conditional Logic: A solid orchestrator lets you build in rules like, “Don’t even think about starting Task C unless both Task A and Task B are complete.” This simple logic is your first line of defense against processing bad or incomplete data.- Establish Clear Alerting: Your alerts need to be smart. Instead of just a generic “something failed” message, they should tell you exactly which task broke and what else is now at risk downstream. This cuts troubleshooting time from hours to minutes.
By handing off dependency management to a tool designed for the job, you get a system that’s easier to understand, more reliable, and doesn’t need constant babysitting.
Handling Unexpected Schema Drift
Schema drift is the silent killer of data pipelines. It’s what happens when your source data’s structure changes without any warning—a column gets renamed, a data type flips from a number to a string, or a new field just appears out of nowhere. A pipeline that was hard-coded to expect the old structure will either break immediately or, even worse, start quietly feeding corrupted data into your systems.
The secret to surviving schema drift is building defensive, adaptable pipelines instead of rigid, fragile ones. You have to design your system with the assumption that things will change.
Here are a few ways to protect your pipelines from the unexpected:
- 2. 3.
Ensuring Data Quality at Scale
As your data volume explodes, checking everything for quality by hand becomes physically impossible. A pipeline that moves data at lightning speed is completely useless if that data is wrong. The only way to guarantee quality in an automated world is to build validation checks directly into the pipeline itself.
This is a fundamental shift from doing occasional spot-checks to a system of continuous, automated verification.
Key Strategies for Automated Quality Checks:
StrategyDescriptionExample Tool/MethodData ProfilingHave your pipeline automatically scan incoming data to report on things like completeness, uniqueness, and value distributions.Running a package like dbt-profiler at the beginning of a job.Automated TestingWrite tests that check for specific business rules, like no nulls in a critical column or no duplicate order IDs.Using dbt test to automatically validate your assumptions after a transformation.Anomaly DetectionGo a step further and use statistical models to spot weird patterns or outliers that could point to a deeper issue.Applying a simple ML model to watch for a sudden, unexpected spike or dip in a key metric.
By baking these checks directly into your data pipeline automation, quality stops being a reactive fire drill and becomes a proactive, integrated part of your process.
Answering Your Data Pipeline Automation Questions

As you start exploring automated data pipelines, you’re bound to run into a lot of questions. It’s a field packed with overlapping terms and a dizzying array of tools, which can feel overwhelming at first. Don’t worry, that’s completely normal.
To help you get your bearings, we’ve put together some straightforward answers to the most common questions we hear. Think of this as a quick guide to slice through the jargon, clarify the big ideas, and give you practical advice you can actually use. Let’s clear things up so you can move forward with confidence.
What’s The Difference Between ETL And Data Pipeline Automation?
It’s easy to get these two mixed up since people often use them interchangeably. But they aren’t the same, and knowing the difference is crucial for making smart decisions about your data setup.
At its heart, ETL (Extract, Transform, Load) is a specific process for moving data. It’s like a recipe: you pull data from a source, clean it up and reshape it (transform), and then load it into a destination like a data warehouse. It’s a classic, battle-tested pattern, but it’s just one way of doing things.
A data pipeline is the much broader infrastructure—it’s the whole factory that moves data from point A to point B. A pipeline can run an ETL process, but it can also handle other patterns, like ELT (Extract, Load, Transform) or real-time data streaming.
Data pipeline automation is the technology and strategy that makes the entire factory run on its own, without any manual pushing of buttons. It’s the system of conveyor belts and robotic arms that executes the recipe automatically. So while an automated pipeline can run an ETL job, its job is much bigger than that single task.
In short: ETL is a specific job, while an automated data pipeline is the self-operating system that can perform that job and many others.
How Do I Choose The Right Tools For My Data Pipeline?
This is a critical question, and the answer is always: it depends entirely on your situation. There’s no single “best” tool, only the best tool for the job you need to do.
Start by thinking through these key factors:
- Data Volume and Velocity: Are you dealing with terabytes of new data every day, or just a few gigabytes a week? Do you need insights in real-time, or is a daily update good enough?- Team Skills: Is your team full of Python experts who can wrangle complex orchestrators, or do you need a low-code platform that your business analysts can use?- Budget and Resources: Can you afford to support a self-hosted, open-source setup, or does a managed cloud service with a predictable monthly bill make more sense?- Future Needs: Don’t just solve for today. Pick tools that can grow with you, otherwise, you’ll find yourself hitting a bottleneck in two years.
For smaller teams or common use cases, managed cloud services like AWS Glue or Google Cloud Dataflow are fantastic starting points. For complex, massive operations, you might need the power and flexibility of a custom setup using an orchestrator like Apache Airflow paired with a transformation tool like dbt. Always define your needs first—don’t just chase the most popular tool.
Can I Build An Automated Data Pipeline Without Coding?
Yes, you absolutely can. The recent explosion of no-code and low-code data platforms has made data pipeline automation accessible to a much wider audience, not just developers.
These tools are built for exactly this purpose:
- Graphical User Interfaces: Platforms like Fivetran, Stitch, and Integrate.io let you build data flows visually by dragging and dropping components and filling out settings in your web browser.- Pre-built Connectors: They come with huge libraries of connectors for common SaaS apps, databases, and APIs. This means you can hook into Salesforce or HubSpot with a few clicks instead of spending weeks writing custom API code.
These platforms are perfect for standard tasks, like pulling all your marketing data into a single data warehouse for analysis. It’s important to know their limits, though. For highly specific business logic, obscure data sources, or really complex transformations, you’ll likely need to bring in some SQL or Python to get the job done right.
How Do You Ensure Data Quality In An Automated Pipeline?
Great automation doesn’t just move data faster; it moves better data. Building confidence in your automated reports means building a multi-layered defense against bad data directly into your pipelines.
- 2. 3. 4.
Ready to stop manually wrangling customer data and start building stronger relationships? Statisfy uses AI-driven automation to turn your raw customer information into proactive, actionable insights. See how our platform can help you streamline operations, predict customer needs, and boost your retention rates.