
Your Guide to Predictive Churn Model Success
By Navin Agrawal · Co-Founder & Head of AI, Statisfy
A predictive churn model is all about using your existing customer data to see the future—or at least, a very likely version of it. It’s designed to answer one of the most critical questions for any subscription business: which of my customers are about to leave?
This isn’t about guesswork or gut feelings. It’s a system that analyzes past behavior to flag at-risk accounts before they actually cancel. This early warning system is what allows you to move from a reactive “Oh no, we lost another one” mindset to a proactive, strategic approach to keeping your customers.
Why a Predictive Churn Model Matters

Reacting to churn after it happens is a losing game. Once a customer has hit that “cancel” button, bringing them back is an uphill and expensive battle. A predictive churn model completely changes the game. It digs into your historical data—things like how often a customer logs in, if their support tickets are increasing, or even changes in their payment history—and assigns a churn risk score to every single account.
This foresight is incredibly powerful. Instead of your success team flying blind, they get a data-backed list of exactly who needs their attention. This lets you step in with the right help at just the right moment, long before a customer decides to walk away.
The Shift from Reactive to Proactive
Without a predictive model, most retention efforts are a shot in the dark. You might blast out a discount offer to everyone, hoping it lands with the few who were on the fence. It’s inefficient. You’re giving away margin to happy customers who would have stayed anyway, and a small discount might not be enough to solve the real problems for those who are truly unhappy.
A predictive model lets you be surgical. You can pinpoint which high-value accounts are starting to drift away and focus your energy there. Your team can then have meaningful conversations, solve real problems, and make an impact where it counts the most. For a deeper dive into the mechanics, this an overview of churn prediction is a great starting point.
A predictive churn model doesn’t just tell you who might leave; it equips you with the crucial “why” and “when,” turning data into a strategic advantage for customer retention.
Key Benefits of Predicting Churn
Putting a predictive model in place isn’t just an interesting data science project; it has a direct and measurable impact on your bottom line. It’s about building a stronger, more sustainable business.
Here are the biggest advantages:
- Improved Customer Retention: This is the most obvious win. By identifying and saving customers you would have otherwise lost, you directly strengthen your recurring revenue base.- Smarter Resource Allocation: Your customer success and marketing teams can stop wasting time on generic outreach. Instead, they can focus their valuable time and budget on the customers who are genuinely at risk.- Enhanced Customer Lifetime Value (CLV): Keeping customers around longer means they spend more with you over time. Every customer you save contributes to a higher average CLV across your entire business.- Actionable Product Insights: The reasons why customers churn are often a goldmine of product feedback. These patterns can shine a light on confusing features, bugs, or missing functionality, giving your product team a clear, data-driven roadmap for improvement.
The Core Components of a Churn Prediction System
 Putting together a solid predictive churn model is a lot like building a high-performance engine. It’s not about a single, magical part. Instead, it’s about a few core components working in perfect harmony. If you use low-quality fuel, a bad blueprint, or shaky assembly, the whole engine just won’t run right.
Putting together a solid predictive churn model is a lot like building a high-performance engine. It’s not about a single, magical part. Instead, it’s about a few core components working in perfect harmony. If you use low-quality fuel, a bad blueprint, or shaky assembly, the whole engine just won’t run right.
It’s the same with a churn model. The system stands on three pillars: the raw data you collect, the way you shape that data (feature engineering), and the machine learning algorithm that does the predicting. Each one is absolutely essential for the system to produce accurate and, more importantly, useful predictions.
Let’s pull back the curtain on each of these pieces.
The Fuel of Your Model Is Data
Data is the lifeblood of your churn model. Without a deep well of good, clean data, even the most sophisticated algorithm is just spinning its wheels. The goal here is to collect everything you can that tells the story of your customer’s experience.
The old saying “garbage in, garbage out” isn’t just a cliché in data science; it’s a fundamental law. The quality of your predictions will never be better than the quality of the data you start with.
The most powerful data usually comes from a few key areas:
- Demographic and Firmographic Data: This is your foundational info—things like company size, industry, location, and which subscription plan they’re on. It helps you organize customers into sensible groups from the get-go.- Behavioral and Product Usage Data: This is often where the real gold is. You’re looking at how people actually use your product: how often they log in, which features they’ve adopted, how long they spend in the app, and the specific actions they take.- Billing and Transactional Data: Details like payment history, recent upgrades or downgrades, and upcoming contract renewal dates can be strong clues about a customer’s financial situation or their level of commitment.- Customer Interaction Data: This captures every conversation and touchpoint. Think support ticket history, survey feedback (like Net Promoter Score), and notes from your customer success team’s calls.
Feature Engineering: The Art of Transformation
Raw data, on its own, is rarely enough. The magic happens during feature engineering, which is the process of taking all that raw information and turning it into meaningful signals—or “features”—that an algorithm can actually understand. This is where your analysts’ expertise really shines.
Think about it like this: your system knows a customer’s “last login date,” but a machine learning model can’t do much with a raw date like “October 26th.” Feature engineering transforms that into a number the model can work with, like “days since last login.” Now that’s a powerful signal of potential disengagement.
Here are a few other examples of what this looks like in practice:
- Calculating the ratio of support tickets opened this month versus the average of the last six months.- Flagging a recent drop in the usage of a key feature by more than 50%.- Counting the number of users on an account who have gone dormant.
This step is a blend of creativity and deep business knowledge. You’re crafting the specific inputs that give the model the clearest possible picture of churn risk. A cleverly engineered feature can be the one thing that elevates your model from just predicting churn to giving your teams real, actionable insights they can use to save an account.
Common Techniques for Modeling Customer Churn
Choosing the right technique for your churn model is a bit like picking the right tool for a home repair project. A sledgehammer and a finishing hammer are both hammers, but you wouldn’t use them for the same task. The best machine learning algorithm depends entirely on what you need to accomplish—are you looking for a simple explanation of why customers leave, or do you need the most accurate prediction possible?
Let’s walk through some of the most common and effective techniques data scientists rely on, starting with a classic before moving into more powerful methods.
First, this infographic helps visualize the critical relationship between churn, retention, and how long a customer stays with you.
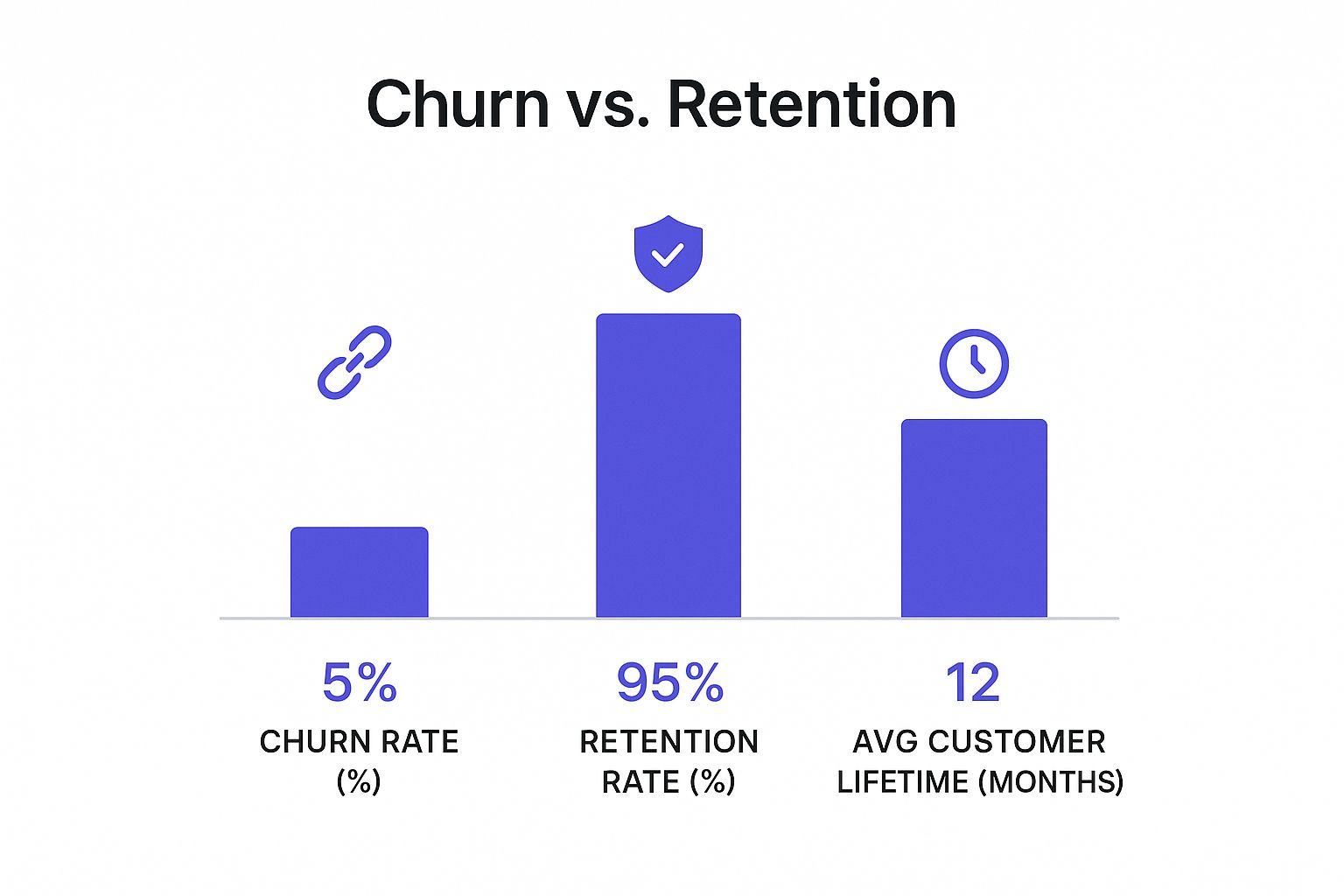
It’s a simple but powerful illustration: as you drive churn down, your retention rate and average customer lifetime go up. This is why accurate prediction is so valuable.
Logistic Regression: Your Go-To for Clear Insights
For many businesses, Logistic Regression is the starting point, and for good reason. It’s the trusty, understandable advisor in your toolkit. It looks at your past customer data and gives you a straightforward probability—like a 70% chance—that a particular customer is about to churn.
Its greatest strength is interpretability. You don’t just get a number; you get a story. The model clearly shows how much each factor, like “days since last purchase” or “number of support tickets,” pushes that churn score up or down. This makes it fantastic for digging into the root causes of churn.
Logistic Regression is prized for its simplicity. It calculates the probability of churn and explains how individual factors contribute to that risk, giving you actionable insights to build retention strategies around.
Ensemble Methods: Boosting Your Predictive Power
While Logistic Regression provides clarity, sometimes you just need more predictive muscle. This is where ensemble methods shine. Think of it as moving from one trusted advisor to a whole committee of experts. Each expert analyzes the problem, and their collective vote determines the final prediction.
Two of the most popular ensemble methods for a predictive churn model are:
- Random Forests: This technique builds hundreds of individual “decision trees”—each one a simple flowchart of customer choices. It then averages their predictions. By pooling so many diverse perspectives, it often achieves much higher accuracy than any single tree could on its own.- Gradient Boosting Machines (GBMs): This approach is even more sophisticated. It builds models one after another, where each new model is trained specifically to fix the mistakes of the one before it. This iterative process of refinement can produce incredibly precise predictions.
A Quick Comparison of Modeling Techniques
To help you decide which approach might fit best, this table breaks down the pros and cons of these common models. ModelBest ForKey AdvantageKey DisadvantageLogistic RegressionProjects needing clear, explainable results and a quick baseline.High Interpretability: Easy to see which factors drive churn.Lower Accuracy: May not capture complex, non-linear relationships in data.Random ForestAchieving high accuracy with less risk of overfitting than a single decision tree.Strong Performance: Excellent accuracy and handles a mix of data types well.Less Interpretable: Becomes a “black box” as the number of trees grows.Gradient BoostingSituations where maximum predictive accuracy is the top priority.Top-Tier Accuracy: Often outperforms other models by learning from its errors.Computationally Intensive: Requires more resources and is sensitive to noisy data. Ultimately, there’s no single “best” model—the right choice is the one that aligns with your team’s resources and business goals.
A predictive churn model is essential for cutting down customer attrition. While logistic regression is a great starting point for its simplicity, businesses often use it alongside more powerful models like Random Forests and Gradient Boosting Machines. These advanced methods are particularly good at finding hidden patterns and complex interactions between variables, which is why large companies rely on them to get the most accurate predictions.
When you’re exploring these options, it’s worth digging into the details. For instance, understanding the key differences between a single Decision Tree vs Random Forest algorithms is crucial for making an informed choice that will directly impact how effective your model is.
Putting Theory into Practice with a Real-World Example

It’s one thing to talk about algorithms and data in theory. It’s another thing entirely to see a predictive churn model actually work in the real world and deliver concrete results. Let’s walk through a great success story that shows just how powerful these models can be for customer retention and, ultimately, the bottom line.
Our example focuses on a big U.S. industrial equipment supplier. They were facing a classic, and costly, problem: customers were slipping away in a tough market, and the company had no reliable way of knowing who was about to leave until it was too late. Their approach was purely reactive, which meant their sales and service teams were always playing catch-up.
They knew they had to get ahead of churn.
The Challenge and the Solution
This supplier was juggling a massive and varied client list, with over 10,000 customers. At that scale, giving every single account personalized attention is simply impossible. They desperately needed a smarter way to figure out where to focus their efforts.
Their answer was an AI-powered churn prediction system. The goal was to build a model that could sift through mountains of customer data to find the subtle, often invisible, signals that a customer was getting ready to bolt. By looking at past behavior, the system could learn what “at-risk” really looked like for their specific business.
And it worked brilliantly. A fantastic case study highlights how this supplier built and launched their model in just 14 days. By digging into data points like declining order sizes and mentions of competitor products, their model found over 50 unique predictors of churn. This gave them the ability to assign a precise risk score to every client, which led to an incredible $40 million in annual savings by stopping customer loss in its tracks. You can dig into the full case study about this AI-powered churn prediction strategy for all the details.
Turning Predictions into Proactive Engagement
The real magic of a churn model isn’t just in the prediction itself—it’s in what you do with it. Once the supplier had a risk score for each customer, they didn’t just sit on the data. They put it to work immediately.
A risk score is more than just a number; it’s a call to action. It tells your teams exactly where to focus their energy to have the greatest impact on revenue retention.
The company built a simple, clear workflow around these new insights:
- 2. 3.
This simple shift changed everything. Their customer relationships moved from being purely transactional to truly consultative. The supplier was no longer just a vendor but a partner who was actively invested in their clients’ success. This story is a perfect example of the massive return you can get when a solid predictive churn model is wired directly into a company’s daily operations.
So, Is Your Churn Model Actually Working?
Building a predictive churn model is one thing, but knowing if it’s actually any good is a completely different ballgame. The real test isn’t just whether it makes predictions, but whether it makes the right ones—the kind of predictions your teams can confidently act on.
This is where a lot of people get tripped up. They look at overall accuracy and think they’ve succeeded. But for churn, simple accuracy can be a trap.
Imagine your typical monthly churn rate is 5%. A lazy model that just predicts no one will churn would technically be 95% accurate. Sounds great, right? Except it’s completely useless. It fails to identify a single at-risk customer, which was the whole point.
Think of your model as a fishing net. You want to catch as many fish (customers who are about to churn) as possible, while leaving the seaweed (happy, loyal customers) alone. To do that, you need to look past basic accuracy and use metrics that truly measure the quality of your catch.
Moving Beyond Simple Accuracy
To get a real sense of your model’s performance, you need to see how well it handles two competing goals. This is where a couple of key metrics, Precision and Recall, give you a much more nuanced picture.
Precision (Catching Only Fish): This metric answers a critical question: “Of all the customers my model flagged as at-risk, how many actually churned?” High precision is vital because it means your retention efforts aren’t being wasted on perfectly happy customers who had no intention of leaving.
Recall (Catching Most of the Fish): This one asks, “Of all the customers who did churn, how many did my model successfully catch?” High recall means you’re not letting at-risk customers slip through the cracks unnoticed. It’s your safety net.
The tricky part? There’s almost always a trade-off between Precision and Recall. If you tune your model for perfect precision, you might only flag customers who are already halfway out the door, missing many others. Go for perfect recall, and you might flag too many happy customers, overwhelming your retention team. The sweet spot is finding the right balance for your specific business goals.
To help find that balance, data scientists often use the F1-Score. It essentially combines precision and recall into a single, more holistic score, giving you a better overall measure of the model’s performance.
Setting a Realistic Benchmark
A model is only as good as the business results it drives. It needs to perform better than a simple guess and align with real-world goals. For instance, in the enterprise space, keeping the annual churn rate below 25% is often a sign of a healthy business. Your model should be a tool that helps you stay well below that kind of threshold.
From a technical standpoint, this often means moving beyond basic models. More advanced techniques like random forests and gradient boosting are generally much better at picking up on the complex, subtle signals of customer behavior that precede churn. For a closer look at the different statistical approaches, you can check out this deeper analysis of data science models for enterprise churn.
Putting Your Predictive Churn Model to Work
A predictive churn model sitting on a data scientist’s hard drive is worthless. It’s just a complex spreadsheet. The real magic happens when you get that model out of the lab and into the hands of your customer-facing teams. This is where a theoretical prediction turns into a customer you actually keep.
The first step isn’t about code; it’s about clarity. What, exactly, are you trying to accomplish? Don’t just say “reduce churn.” Get specific. Are you aiming to cut churn among your top-tier accounts by 10% this quarter? Or is the real goal to save more customers in their first 90 days? A sharp, focused objective gives you a clear target and a way to know if you’ve actually hit it.
Once you know your destination, you have to check your fuel: the data. There’s no way around it—your model is only as good as the information you feed it. Make sure your data is clean, organized, and ready to go. This isn’t glamorous work, but skipping it is a recipe for disaster.
Turning Numbers into Conversations
It’s tempting to jump straight to building a super-sophisticated, “black box” model. That’s usually a mistake. If your customer success team can’t understand why a customer is flagged, they won’t trust the model. And if they don’t trust it, they won’t use it.
Start with something simpler and more transparent, like a logistic regression model. This approach builds trust because it can explain its reasoning—“this customer is at risk because their product usage has dropped.”
A predictive churn model isn’t meant to just spit out a list of names. That list needs to kickstart a real, human process. This means wiring the model’s outputs directly into the tools your teams use every single day.
An insight without a corresponding action is just trivia. The entire point of a predictive churn model is to give your teams the intel they need to step in and help a customer before it’s too late.
Here’s how that plays out in the real world:
- Smart Alerts: A customer’s churn score hits a critical level. An alert should instantly pop up for their Customer Success Manager (CSM) right inside their CRM or a dedicated Slack channel.- The “Why” Behind the Alert: The notification shouldn’t just be a name. It should include the reasons, like “hasn’t logged in for 14 days” or “has three unresolved support tickets.” This context is everything for a productive conversation.- A Clear Game Plan: Your team needs a playbook. When an alert comes in, what happens next? Is it a personalized email? A phone call? Maybe it’s a targeted offer for some extra training. Whatever it is, the process needs to be defined.
Finally, remember that this is a cycle, not a one-and-done project. Your CSMs are on the front lines. You need a system for them to give feedback on the model’s predictions. Was the alert accurate? Did the outreach work? This feedback is gold—it’s what you’ll use to retrain and refine your model, keeping it sharp and effective over time.
A Few Common Questions About Predictive Churn Models
People often assume you need mountains of data to get started with a predictive churn model, but that’s not always the case. Of course, more data helps, but you can build a surprisingly effective baseline model with just a few months of solid historical customer info. The real secret is quality over quantity—clean, well-structured data showing key customer interactions will always beat years of messy, incomplete records.
So, how often should you retrain your model? There’s no magic number here; it really comes down to the rhythm of your business. A quarterly retrain is a great starting point for most companies. But if you’re in a fast-moving market or constantly shipping new product features, you might find that monthly updates keep your predictions much sharper and more relevant.
Do I Need a Data Science Team?
Not necessarily, and definitely not like you used to. In the past, building any kind of predictive model was a heavy lift that absolutely required a dedicated data science team. Today, things are different.
Many modern customer success platforms have made churn prediction far more accessible, offering built-in or automated modeling tools.
This is a huge shift. You no longer need to be a machine learning guru to get ahead of churn. The focus has moved away from writing complex code and toward using the actionable insights these systems produce.
This newfound accessibility means your team can start spotting at-risk customers and experimenting with retention plays almost immediately. It gives your customer success managers the power to act proactively, without needing a degree in statistics or knowing how to code in Python.
You can start small, prove the model’s value with early wins, and then make a more informed decision later on about whether a fully custom, in-house solution makes sense for your business.
Ready to turn churn predictions into proactive retention? Statisfy uses AI to transform your customer data into clear, actionable insights, so your team can focus on saving at-risk accounts, not drowning in spreadsheets. Learn how Statisfy can help.